

TweetScraper: Scraping Twitter posts and follower counts
Link to tool: https://github.com/Durhamster/TweetScraper
Undoubtedly, there is an abundance of OSINT tools focused on extracting data from Twitter, each tool has its own unique set of capabilities and outputs. In this latest OSINT tool review, we will present ‘TweetScraper’, a lightweight Python script that can be used to easily scrape from single and multiple Twitter accounts in addition to querying the overall number of followers for given users. As is the case for the majority of Twitter-focused OSINT tools, Digital Investigators who intend to use TweetScraper will require a Twitter Developer Account in order to obtain the prerequisite keys needed to deploy the tool.
Obtaining a Twitter Developer Account is best described as a tedious process due to Twitter’s due diligence process that can take up to a week from start to finish. However, once the developer account has been created and the keys have been obtained, installing and deploying TweetScraper is incredibly easy. As is the case with the majority of Python-based scripts, the prerequisite modules are installed by invoking pip install -r requirements.txt. Thereafter, TweetScraper can be called by invoking python app.py, resulting in a series of options that the user can select:
- Scrape a single account
- Scrape a list of accounts
- Get the follower count for a list of accounts
- Check a list of handles to see if any are suspended, private, or incorrect
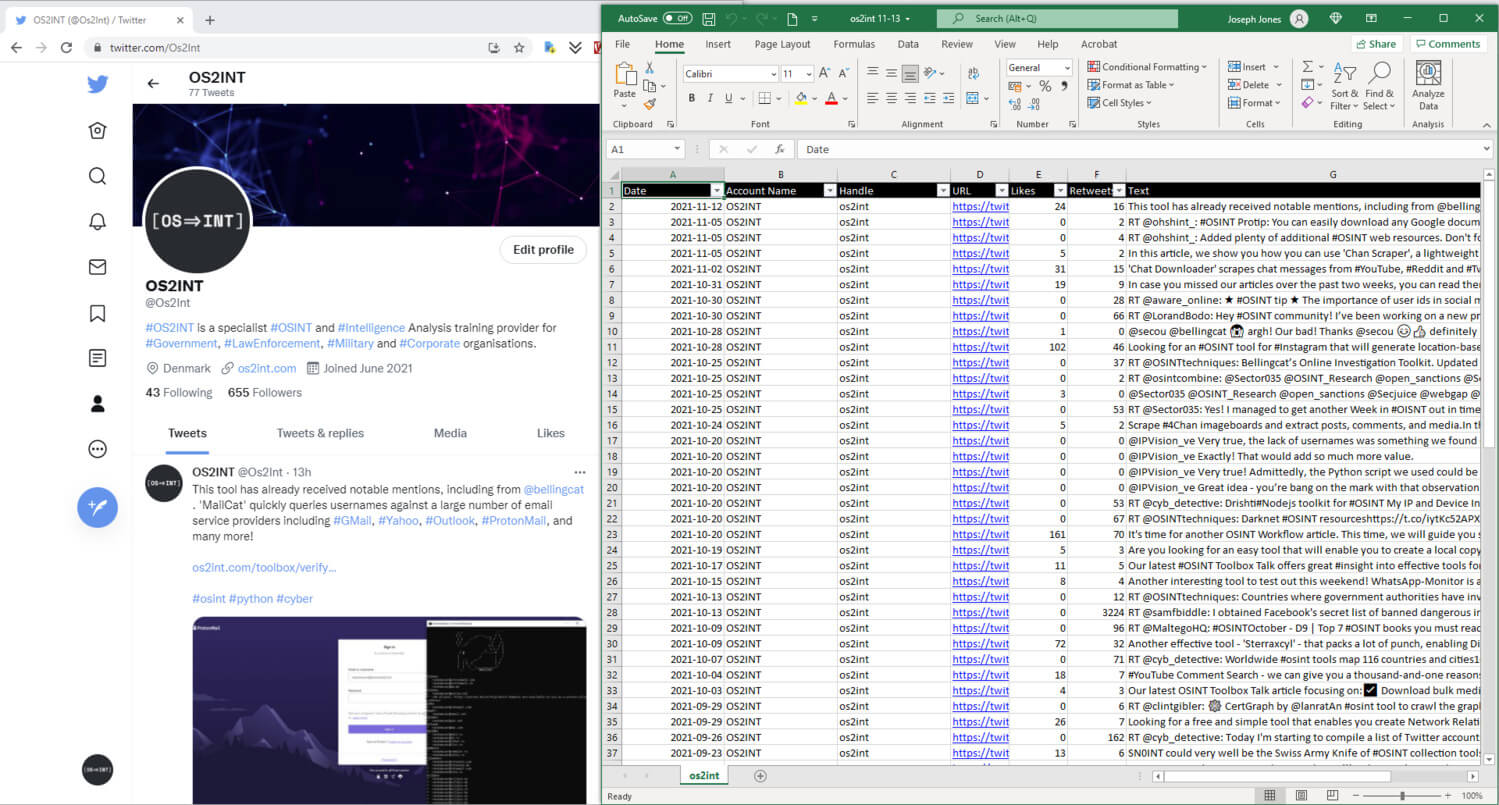
Scraping individual accounts can be achieved directly within the command-line interface simply by indicating the target account that you want to scrape. For multiple accounts, the user should list the target accounts within the handles.txt file located within the same directory – the file should then be called from within the command-line-interface. By default, the tool is configured to scrape the first 500 tweets, though this can be easily changed within the app.py script. Lastly, the tool is also configured to pause in-between account scrapes, this is designed to reduce the risk of users exceeding Twitter’s rate limiting mechanisms. In terms of output, TweetScrape provides each scrape with a Microsoft Excel file (.xlsx) with details of each tweet including creation date, account name, Twitter handle, URL, number of likes, number of retweets, and the overall tweet content.
All-in-all, TweetScraper is a nice and simple tool that can be used by Digital Investigators to quickly extract tweets and neatly output them in a readable format. Whilst there are other Python-based scripts and utilities that can offer a more integrated range of features such as exporting data to SQL and sentiment analysis, TweetScraper is unique based on its simplicity. Unfortunately, like other Twitter-focused OSINT tools, obtaining a Twitter Develop Account in order to use TweetScraper can be a frustrating process. That said, with the necessary prerequisites obtained, deploying TweetScraper is incredibly easy and its output is quite effective.
